Next: Maintaining a code generator Up: Component Generator Tools Previous: Design overview Contents
Creating a new code generator tool depends on the code generation task you want to accomplish. Nevertheless, the process generally needs to cover three broad tasks before you can get a working code generator:
In addition, depending on the complexity of the code generator you want to write, you might need to perform some additional coding tasks. This could include any of the following concepts, and likely others not listed.
The remainder of this section addresses these areas. Background on how the code generator base classes work is also included when it will help explain how to do things.
To start writing a new code generator, you will need to create a new Java class to hold your generator's specific information, and fill it in with some basic information about the language you want to generate. Most of this process is more or less boilerplate code; in fact, you might want to create the skeletal Java code by copying an existing generator and stripping out the functions. See the IDL2 generator class for an example of a minimal generator.4.2
The remainder of this process involves creating several arrays of information relating to your specific generation task. You will need to create arrays containing top level node types, environment files and templates, language mappings, and keywords for your target langauge. Each of these is explained below.
After you have a basic Java class skeleton, you need to determine the nodes for which generated code should be written to disk. These will be referred to as ``top level node types''. Store these node types as strings in a private final static String[] array in your new class. Note that ``MContainer'' will be added to these types, since the top node of all CCM Tools metamodel graphs is an MContainer class instance.
Next, you need to identify files that need to be output only once per generation task; these files are referred to as ``environment files.'' Most generated files, like the code for a component, are written one or more times during code generation--once for each component (or operation, or whatever) in a graph. Environment files, on the other hand, are things like global header files, global utility functions, and so on. These files cannot be filled with any information from a graph traversal; they are more or less static.
To get started, figure out the relative paths of each of the code generator's environment files (relative to the root directory of the generated code; do not use absolute file paths!). Specify these files in your class in a private final static File[] array. Next, you need to provide your generator with a list of the templates to use for writing each of these environment files. Define an array of strings that contains the names of templates to use for each environment file. These two arrays must be the same length.
Normally, templates for environment files do not contain any keys; the templates are simply written to disk as is, since environment files are globally valid. Example 4.3.1 shows the environment file arrays in the C++ Python wrapper generator.
Create a set of language mappings in a private final static String[] array. This language map array must be the same length as the MPrimitiveKind enumeration (located in Metamodel/ BaseIDL/ MPrimitiveKind.java in the source tree). The language map array provides the strings that will be used to translate IDL3 language types into the data types for the target language. Thus the entries in this language mapping array must be in the same order as the entries in the MPrimitiveKind enumeration. Example 4.3.2 shows the language type mapping for the C++ generators.
The last piece of information your generator needs is a list of the keywords in your generator's target langauge. Components, interfaces, operations, and exceptions cannot normally have the same name as a keyword, so if the generator finds a graph node with a keyword identifier, it will map the identifier to a new, safe identifier by prefixing the name with an underscore (_). Like the other arrays, the keyword array should be a private final static String[] data element in your class.
Finally, you need to provide all of these arrays to the constructor of the abstract code generator base class in each constructor you write for your generator class. The constructor for the C++ abstract base generator class in Example 4.3.3 shows how to call the superclass' constructor, providing the language mappings, keywords, and environment files to build the generator.
Writing a template set can be divided into two types of writing tasks. First, you need to create templates for your code generator's environment files. Next, you need to create the normal templates for your generator. Now you might think that this second step is easy, but it actually represents about 75 % of the work involved in creating a code generator.
Create templates for your environment files. Since environment files are usually static from project to project, these templates are often just straight code written in the target language.
If you absolutely need to include dynamic data in an environment file, you will need to perform a somewhat different operation. Instead of adding your semi-dynamic environment file to the normal environment files list, you can make use of the finalize function. This process is not entirely the same as generating normal environment files, however. See section 4.3.4 for details.
Now take a deep breath; you are about to start writing a template set. The tutorial takes a small style detour at this point to explain in detail how the template mechanism works. This is important for writing templates and accompanying them with custom code in your generator class.
Writing a template set usually starts by writing templates for more globally scoped CCM metamodel elements (e.g. MContainer and MModuleDef).4.3 Then, whenever a potential subelement is encountered (for example, an MInterfaceDef instance could be contained in an MModuleDef instance in an IDL3 source file), the template can reflect this possibility by including a `key' for the element type.
Template writing can theoretically proceed in this way from general elements through the entire CCM metamodel to more specific elements (e.g. MParameterDef and MField) by following this process. Just by following this template process, you can often write a near-complete template set.
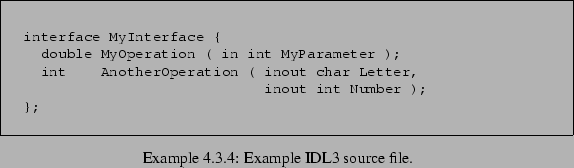
For purposes of illustration, the remainder of this section will use the IDL3 file shown in Example 4.3.4 as an example for template writing. The parse tree produced by parsing such an IDL3 file, with just the node types and identifiers indicated, is shown in Example 4.3.5. The target language for the example will be Java. For comparison, Example 4.3.6 shows the generated Java code that should result from the example IDL3 file.
As stated earlier, template writing can generally proceed from more global library elements to more specific elements. Given the example IDL3 file as a guide, you'll need to write a template for MInterfaceDef (since it is the highest level element in our IDL3 code example). For the time being, the MContainer template is empty.
The first step is to create a directory to hold the templates. The directory
needs to be named <language>Templates and needs to be installed under PREFIX/share/ccmtools-A.B, where the code generators can find it.
Example ![[*]](crossref.png) shows a snippet of the Makefile.am for the local C++ generator.
shows a snippet of the Makefile.am for the local C++ generator.
In general, the template for a node type needs to have the same name as the node type, so to create a template for MInterfaceDef nodes, you need to make a new file, JavaTemplates/MInterfaceDef. Peek a little ahead to Example 4.3.7 and take a look at one potential way to define a template for MInterfaceDef.
As mentioned earlier, a template is a piece of code written in the target language (for this example, Java). But because one node type can have many different instances--that is, there could be multiple MInterfaceDef class instances in a graph--each template contains keys that the code generator will fill in when the code is generated. There are four different types of keys available, as described below.
A key is just a text string of the form %(name)s.4.4 Keys come in four flavors:
%(Identifier)s), or sequence
bounds (%(Bound)s) are valid candidates for keys in this category.
Since this is a relatively common and simple operation, the home
identifier can be included in a template using the %(HomeType)s
key. As another example, many node types (especially operations,
parameters, and attributes) need to include their target language data
type in the template. The %(LanguageType)s key provides access to
this information. Other special keys are available;
Table 4.1 describes these special keys.
Next comes an explanation of how this recursive template loading concept works. After grokking it you should be able to handle 90 % of template writing tasks.
The template substitution process goes even further than basic translation directly from graph nodes, as implied by the first key type. Consider, for example, a code template for an IDL3 operation. This template will need keys for things like the operation's identifier and the data type that the operation returns. The values for these keys come directly from each operation node in a given graph traversal.
But an operation also has parameters and can throw exceptions. The number of parameters and exceptions is not fixed for all operations. That is, a given operation might take three parameters and throw four types of exceptions, while another operation might only take one parameter and throw no exceptions. The template for an operation cannot hold the code for all possibilities in this respect.
In fact, the specific code to implement these types of variables needs to be created after all appropriate nodes in the graph are visited. More specifically, for an operation, the operation template needs to know information contained in the child parameter and exception nodes in the graph. Luckily, though, all the the relevant nodes (parameters and exceptions) are all immediate children of the operation node, so the operation needs just the information from its child nodes.
To support this type of template interaction, the code generator implementation supports recursive template substitution. Keys in a template just need to have the name of child node types, and the code generator will automatically substitute template information from the filled-in templates of child nodes in the graph. The specifics of this substitution process are described below during the tutorial on template creation.
Because an MInterfaceDef object has a variable called identifier (and a corresponding access function named getIdentifier), it is easy for the code generator to simply substitute the value of the current node's identifier for the Identifier key in a template.
The difficulty with a top down template like the one shown for our example MInterfaceDef is that it is not clear how to generically generate code for a more complex key like MOperationDef: MInterfaceDef class instances do not have variables and access functions for direct data members called ``mOperationDef''. To support such keys, the code generator uses a recursive template loading and substitution process. This scheme simplifies template development in many cases and allows for more general template keys. However, it also requires some extra coding in some cases.
Consider the parse tree for the example code generation task, shown in Example 4.3.5. Keep in mind that the graph traverser is depth-first, so all child nodes will be visited before visiting a sibling node in the graph. When the graph traverser starts reading the MyInterface node, then, it will proceed to the MyOperation node and on to the MyParameter node before returning back up the tree. The traverser will leave the MyParameter node, then leave the MyOperation node. Next it will visit the OtherOperation node (and also that node's child elements), and finally it will go all the way back up and leave the MyInterface node at the top.
At each point during this process, the code generator stores information about the nodes it has visited so far. In this way, when the code generator returns to the MyInterface node after visiting its child nodes, it has all the necessary information to fill in an MOperationDef key in the interface template.
The exact process that the code generator uses to gather this information is described next. Following the description is an explanation of how to use this information in template creation.
When the code generator receives notification that the traverser is leaving a node, the generator attempts to load a template for the given node type. Because the MyParameter node in the example is a MParameterDef instance, the code generator in our example will try to load a template from disk located at JavaTemplates/MParameterDef. So if the template for MParameterDef looks like
The important thing to note now is that the substituted template value will be added to the information in the parent node. This information will be indexed using the node type as a key in the code generator's variable hash table. So the above string will be added to the code generator's variable hash, indexed under the MParameterDef variable of the MyOperation node.
After descending to read the first parameter node, the graph traverser will exit the MyOperation node, at which point it will load the template from JavaTemplates/MOperationDef (because MyOperation is an instance of the MOperationDef class) and substitute the variables for this node. The template for MOperationDef nodes should look like the target Java code, with specific identifiers replaced by keys. So if the MOperationDef template looks like this:
The graph traverser will then continue on and start the AnotherOperation node. When it has ended the second MParameterDef child node, the MParameterDef variable for the AnotherOperation node will look like:
This recursive substitution process is what enables short, top down style templates that can handle a variety of input trees.
You might have encountered a few questions while reading through this business about template substitution. Answers to two of these questions are mentioned here, but now is a good time to mention other sources of support as well: If you decide to hack on the CCM Tools, it is probably a good idea to subscribe to the ccmtools-devel mailing list4.5; the folks on the list can help address any development questions you might have.
Back to the questions. First, you might be wondering how just one template for each node type can be enough to satisfy the wide variety of code generation tasks that you might be faced with. For example, in C++ the syntax for a function prototype is different from the syntax for a function call--the parameter data types are not provided in the second case. In this case, an MOperationDef node in the CCM metamodel graph needs to have two types of template information about its child MParameterDef nodes.
Luckily, the CCM Tools include a solution for this problem, as mentioned in the list of four different key types. You can simply define two templates for MParameterDef nodes, each with a different name, and each containing a different template. For example, templates called MParameterDefName and MParameterDefAll might contain the template information shown in Example 4.3.9. The MOperationDef template(s) can include either or both of these keys, and the appropriate information will be substituted into the template. In brief, when a code generator receives a node start event from the graph traverser, the code generator will load all the templates in the template set that start with the node type. This makes the generators potentially a bit slower, but it allows for unlimited numbers of templates for a given node type. For a rather complex example of this, take a look at all the MUsesDef templates in the local C++ template set.
A second question you might be asking, specifically about the example code shown earlier, is what to do with that extra comma after the final operation parameters. This hints at a larger problem, that of template post processing. The solution is addressed in section 4.3.5. But first, you should get your mind off templates for a bit, have a burrito, and read the following section to get your code generator up to speed.
If you've tried compiling your new code generator class, you should have noticed that it will not compile. The class has not implemented a few functions that are defined as abstract in the parent class. To implement your generator, you must at the very least provide implementations for these functions.
First you must write a getLanguageType function. This function provides the generator with a mapping between IDL3 data types and the data types in the target language. Sometimes this can be a basic function that simply provides the mapped value from the language map you created earlier.4.6 More often, however, the complex data types will require more special treatment. Example 4.3.10 shows the rather complex implementation in the local C++ generator.
Next you need to provide your generator with a writeOutput function implementation. This function is called for each top level node type encountered in the graph. This function will produce all generated code; no other function is generally implemented so that it writes things to disk. The writeOutput function should accept a Template object and have a void return type. This function can be as simple or as complex as you wish; it is the generator's primary source of control over the generation process. The implementation in the C++ mirror test generator is shown in Example 4.3.11 as an illustration.
An important utility defined in the code generator base class is the writeFinalizedFile funciton. This function accepts three strings as input: the relative directory of the file to write, the name of the file to write, and the string to write to the file. This function spares most of the energy required to write a file using Java.
Last, you need to write a finalize function implementation. This function is called when a set of graphs has been completely traversed. A set of graphs would come from processing a set of IDL3 source files together, with one run of the code generators. This function provides a code generator with an opportunity to generate files based on the entire set of input IDL3 source files.4.7
Normally this function is used to create a set of global (i.e., per-package) header files that include other files that might have been created during each separate graph traversal. In addition to having the set of input IDL3 files available in this function, you can use the ``define'' mechanism available in the ccmtools-generate tool, and provide -D flags on the command line.
Note that many code generators will not need to use the finalize function.
For most generators, an empty implementation ({ return; }) will suffice.
Now that you've finished implementing the basics in your code generator, we'll get back to the problem of too many commas in the output code.
Take a look back at Example 4.3.8, and recall that the template set is complete, except for the cursed extra commas hanging around at the end of the parameter list. This hints at a larger problem, that of post processing the template information. In this case, the code generator class itself must supervise the template substitution process, removing the last comma from a paremeter list before it gets passed to an operation's template.
To implement this kind of post processing functionality, you will need to provide a function definition for the getLocalValue function in your code generator class. This function is actually called whenever the code generator receives notice that the traverser has left a graph node. Let's back up a little, even: when the graph traverser leaves a graph node, the generator loads up all templates for the node, looks through the templates, and figures out which keys are defined. The generator then calls getLocalValue for each key, providing the key and the current value of the variable from the generator's internal variable hash table. The resulting value from this function is then stored back in the hash table.4.8
By overriding this function, then, you can add a lot of powerful post processing capabilities to your code generator. For now, though, since you just want to get your generator working, Example 4.3.12 shows one possible way we could implement this function, along with the helper function that removes the troublesome trailing comma.
By now you are likely sick of reading and coding. Take a nap. And take heart; you have finished dealing with this tutorial and know all that there is to know about the code generator library! Implementing code generators is simply a matter of applying the principles given above to each corner case that crops up in your generator. Again, remember to post questions to the ccmtools-devel mailing list.4.9
2003-11-09